What Azure, AWS Outages Reveal About Resilience
Oct. 29, 2025

For years, the promise of the cloud has been reliability, scalability, and always-on service. But the past few months have reminded us that even the strongest systems have weak spots.
Today’s global Microsoft Azure outage caused businesses to lose access to core applications and infrastructure. Tens of thousands of users experienced connectivity issues, authentication failures prevented users from logging into enterprise systems, and customer-facing websites for many businesses were inaccessible.
Microsoft deployed a fix to address an outage of their Azure cloud portal that left users unable to access Office 365, Minecraft, and other services. Users reported issues with Xbox Live. Costco, Starbucks, and other services.
Initially, Microsoft reported it as DNS issues on their Azure status page, stating: "Starting at approximately 16:00 UTC, we began experiencing DNS issues resulting in availability degradation of some services."
However, Microsoft later revised their explanation. According to an update at 13:06 EDT (around 1 PM Eastern), Microsoft changed its assessment, specifically identifying an Azure Front Door configuration problem as the root cause.
The updated statement said: "We suspect that an inadvertent configuration change as the trigger event for this issue."
Alaska Airlines made it clear on X that travelers should blame Azure, not Alaska Air, for delays and check-in issues.
Unfortunate Timing
The Azure outage hit mere hours before Microsoft was set to release its quarterly earnings report. And just over a week after a massive outage of Amazon’s cloud computing service, Amazon Web Services (AWS), took down online services, including social media, gaming, food delivery, streaming and financial platforms, according to the Associated Press (AP).
From Alexa to The New York Times, Slack, and GoDaddy, the AWS outage reminded us how deeply embedded cloud infrastructure is in our daily lives.
Then today’s Azure failure drove that point home even more. Together, these incidents show that downtime is not a thing of the past. It’s part of the reality of modern digital operations. Amazon is the dominant provider of cloud computing services, but Microsoft ranks second, ahead of Google, in most markets, according to the AP.
Both outages highlight the vulnerability of our internet infrastructure when major cloud providers experience technical difficulties. With AWS controlling about 30% of the cloud market and Azure around 23%, disruptions to these services have far-reaching consequences across multiple industries and services.
Impact
- Millions of users worldwide couldn't access essential online services
- Major global companies including Netflix, Starbucks, and United Airlines experienced disruptions
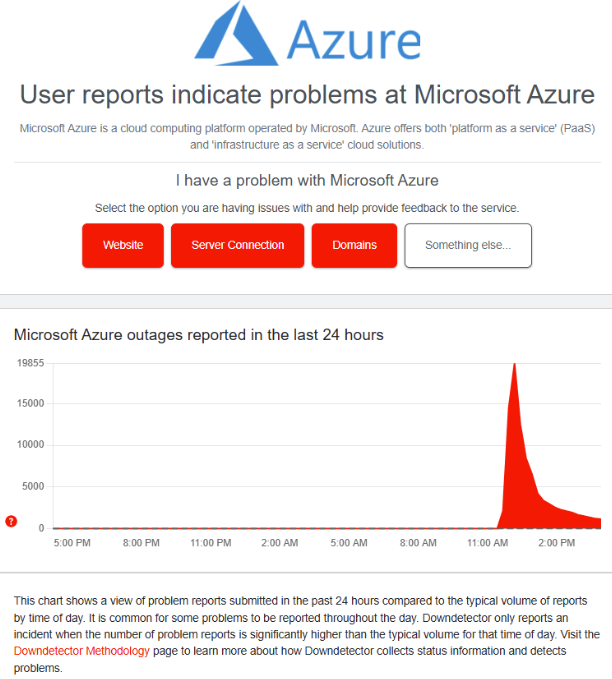
- Downdetector recorded about 50,000 reports at the outage’s peak
- Businesses that relied on AWS for storage, databases, and hosting were affected
- Both consumer and enterprise applications experienced downtime
The Cloud Has Become a Utility
STACK Cybersecurity recently shared insight with Corp! Magazine in the article “AWS Outage Shows Fragility of Cloud Computing.” The discussion focused on how dependent many companies have become on a single cloud ecosystem, often without realizing how much risk that creates.
“These outages aren’t just technical issues,” said Rich Miller, Founder and CEO of STACK Cybersecurity. “They’re operational challenges. When cloud systems fail, companies feel it in real time in productivity, in customer trust, and in their bottom line.”
His point hits home. The Cloud is a utility. When it fails, the effects ripple far beyond IT.
Why This Matters for Business Leaders
For executives and business owners, the takeaway is simple: resilience isn’t automatic just because you use the cloud. It must be designed, tested, and managed.
Think about your own company:
- How many of your systems depend on one provider?
- If that provider goes offline, do you have another route to continue operations?
- Can your team keep working if communication tools or shared platforms are unavailable?
Every firm that relies on cloud computing needs clear answers to those questions. A few hours of downtime can mean missed deadlines, delayed transactions, and frustrated clients.
Diversity Builds Resilience
At STACK Cybersecurity, we believe that true resilience comes from diversity, not dependency. That means creating systems and data flows that stay flexible even when one vendor has problems.
Our alignment with Adaptive Data Networks (ADN) reflects that mindset. ADN’s adaptive routing and redundant network design have held strong through recent disruptions, giving businesses an extra layer of continuity when cloud giants stumbled. It’s not about replacing the cloud. It’s about supporting it with smarter infrastructure.
Strengthening Resilience
Every company can strengthen its resilience by doing three simple things:
- Review your dependencies. Identify where your data and operations live, and what happens if those systems fail.
- Test your continuity plan. Run tabletop exercises or downtime simulations to find gaps before real incidents occur.
- Build in redundancy. Use multiple regions, platforms, or providers where practical, and partner with teams who prioritize uptime.
No Uninterrupted Service
Cloud computing has transformed the way businesses operate. But as recent events prove, no single provider can promise uninterrupted service. The companies that will stay ahead are those that plan for failure, communicate clearly, and invest in layered resilience.
At STACK Cybersecurity, we help firms prepare for that reality, not with fear, but with foresight.